 |
 |
| Fig. 1 Differently-focused images by light field rendering. (circled parts are in-focus) | Fig. 2 All in-focus image by integrating in-focus parts. |
Takeshi NAEMURA
Akira KUBOTA
Light field rendering is a method for generating free-viewpoint images from pre-acquired images captured by an array of cameras. Since it is based on the constant depth assumption, we can see some focus-like effects on the synthesized images when the distance between cameras is not small enough. This means that, when the light field is undersampled, objects apart from the assumed depth cannot be synthesized clearly. These out-of-focus objects appear with blurring and ghosting.
In order to solve this problem, we extended light field rendering method by introducing multiple assumed depths (focal planes) and a novel focus measurement algorithm. Since we use multipe depths, we need to assign the optimal depth for each pixel. This depth assignment process is performed by on-the-fly focus measurement without any pre-estimated geometry. Our method runs at interactive frame-rates.
Our algorithm consists of two steps. First, for a given viewpoint, we synthesize tens of differently-focused images by moving the assumed depth (the focal plane) of light field rendering. Then, the in-focus regions of those images are integrated into a final image in real time. Fig. 1 and 2 show the outline of our method.
|
|
| Fig. 1 Differently-focused images by light field rendering. (circled parts are in-focus) | Fig. 2 All in-focus image by integrating in-focus parts. |
The essential point of our method is how to select in-focus regions from differently-focused synthetic images. For this purpose, we generate 2 or 3 images at each depth of the focal plane using different kind of reconstruction filters. If a region of an object is in-focus at a certain depth, the object appears almost identically, otherwise it appears differently (See Fig. 3). Therefore, we use the difference between those images to detect in-focus regions. For the theoretical analysis of this focus measurement algorithm on the frequency domain, see my papers[1,4].
 |
 |
 |
| normal filter | wide-aperture filter | camera-skipped filter |
Our algorithm does not need any pre-estimated geometry. In contrast, we estimate a view-dependent depth map by comparing synthesized images by different reconstructions filters. We apply a real-time smoothing operation to the depth map in order to suppress noises on the final synthetic image. The diagram of our method is shown in Fig. 4. Although our algorithm is simple and the estimated depth is not completely accurate, we can produce all in-focus images at arbitrary viewpoints with high quality.
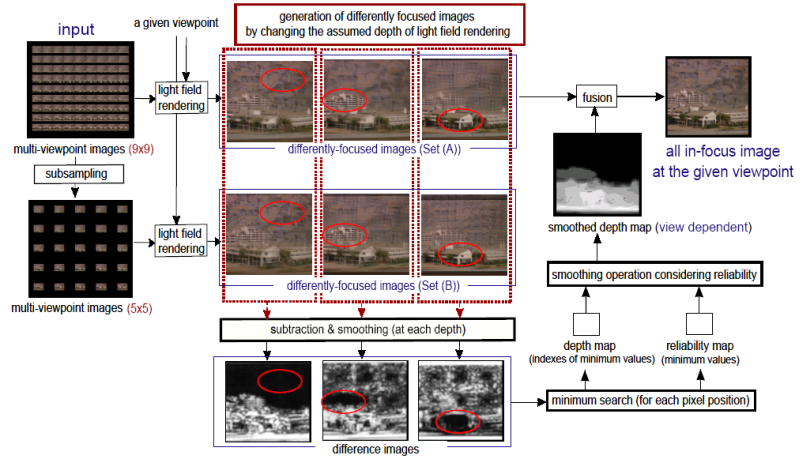
We developed a software on a Pentium 4 3.2 GHz PC with an OpenGL supporting graphics card that has a NVIDIA GeForce FX 5800 processor built-in. As the light field data, we use "the multi-view image data courtesy of University of Tsukuba, Japan." The light field consists of 81 (9 x 9) images, each of which has 256 x 192 pixels. In this experiment, the number of the assumed depths is set to 10, and the normal filter (for Set (A)) and the camera-skipped filter (for set (B)) are used. That is, we generate the set (A) from 9 x 9 images, and the set (B) from 5 x 5 images. The size of synthesized images is set to 256 x 256 pixels.
Shown in Fig. 5 are some experimental results. We can see that those synthesized images are all in-focus; the whole scene appears clearly and sharply. We achieved interactive frame-rates (8.76 fps). Quantitative evaluations of the rendering quality using a CG object are shown in Paper [1].
|
 |
 |
 |
 |
 |
Fig. 5 all in-focus rendering by our method. (From left to right, miniature city, doll, and plants are rendered)
Special thanks go to Prof. H. Harashima of the University of Tokyo, Japan for his helpful discussions and University of Tsukuba, Japan for multi-view image data.