
A light-field display provides not only binocular depth sensation but also natural motion parallax with respect to head motion, which invokes a strong feeling of immersion. Such a display can be implemented with a set of stacked layers, each of which has pixels that can carry out light-ray operations (multiplication and addition). With this structure, the appearance of the display varies over the observed directions (i.e., a light field is produced) because the light rays pass through different combinations of pixels depending on both the originating points and outgoing directions. To display a specific 3-D scene, these layer patterns should be optimized to produce a light field that is as close as possible to that produced by the target three-dimensional scene. To deepen the understanding for this type of light field display, we focused on two important factors: light-ray operations carried out using layers and optimization methods for the layer patterns. Specifically, we compared multiplicative and additive layers, which are optimized using analytical methods derived from mathematical optimization or faster data-driven methods implemented as convolutional neural networks (CNNs). We compared combinations within these two factors in terms of the accuracy of light-field reproduction and computation time. Our results indicate that multiplicative layers achieve better accuracy than additive ones, and CNN-based methods perform faster than the analytical ones. We suggest that the best choice in terms of the balance between accuracy and computation speed is using multiplicative layers optimized using a CNN-based method.
Toshiaki Fujii (Professor)
Keita Takahashi (Associate Professor)
Keita Maruyama (graduate student)
We propose an efficient pipeline from input to output for a tensor light-field display. Conventionally, a dense light field (i.e., tens of images taken with narrow viewpoint intervals) is required as an input in such displays. However, obtaining dense light fields is a challenging task for real scenes. To make the acquisition process more efficient, we adopted a coded-aperture camera as an input device, which is suitable for acquiring dense light fields in a compressive manner. Moreover, we modeled the entire process from acquisition to display using a convolutional neural network. As a result of training the network on a massive light field data, we can reproduce the whole light field on the display from only a few images taken with the camera. Both simulative and real experiments were conducted to show the effectiveness of our method.
Toshiaki Fujii (Professor)
Keita Takahashi (Associate Professor)
Keita Maruyama (graduate student)
Yasutaka Inagaki (graduate student)
Hajime Nagahara (Professor, Osaka University)
We propose a method of using a focal stack, i.e., a set of differently focused images, as the input for a novel light field display called a “tensor display.” Although this display consists of only a few light attenuating layers located in front of a backlight, it can be viewed from many directions (angles) simultaneously without the resolution of each viewing direction being sacrificed. Conventionally, a transmittance pattern is calculated for each layer from a light field, namely, a set of dense multi-view images (typically dozens) that are to be observed from different directions. However, preparing such a massive amount of images is often cumbersome for real objects. We developed a method that does not require a complete light field as the input; instead, a focal stack composed of only a few differently focused images is directly transformed into layer patterns. Our method greatly reduces the cost of acquiring data while also maintaining the quality of the output light field. We validated the method with experiments using synthetic light field datasets and a focal stack acquired by an ordinary camera.
Toshiaki Fujii (Professor)
Keita Takahashi (Associate Professor)
Yuto Kobayashi (former graduate student: --2018.3)
Our system was demonstrated at International Display Workshop 2016.
Process pipeline from capture to display.
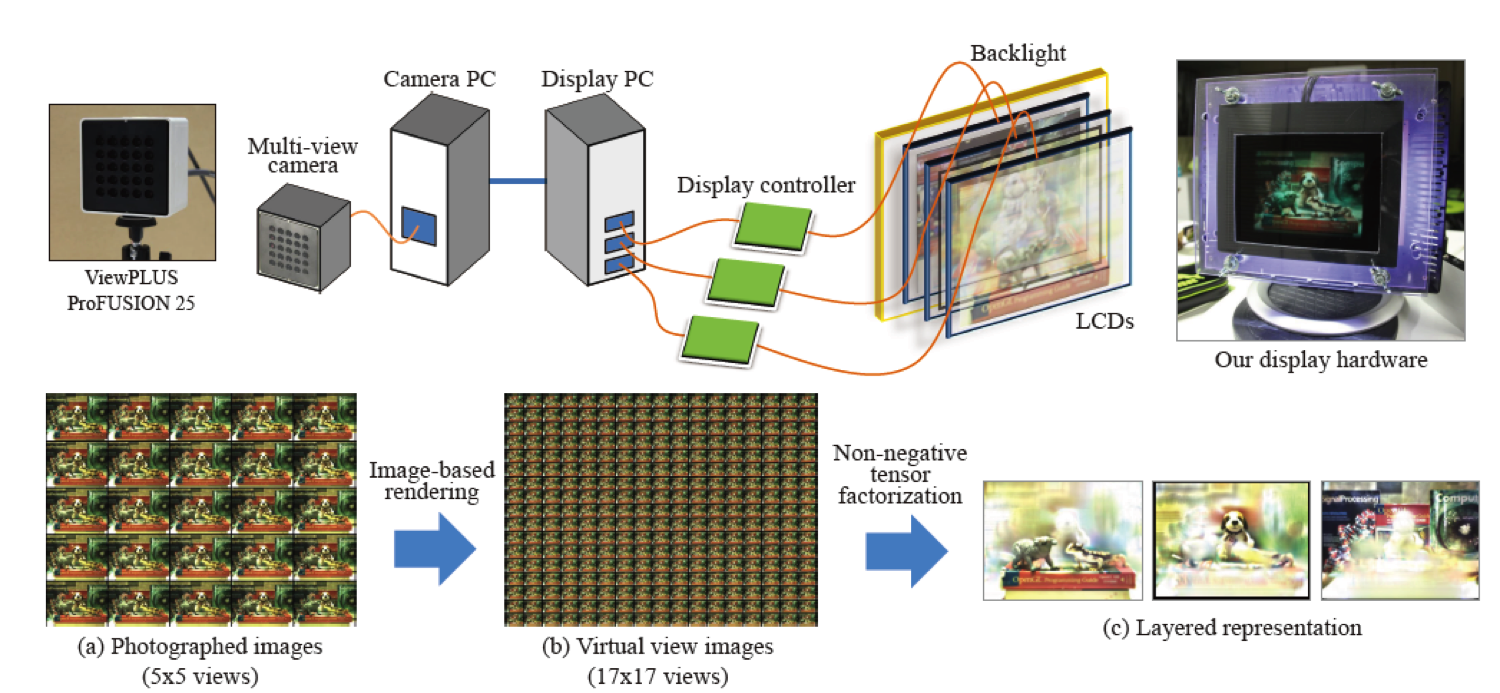
We have developed a prototype of a layered light-field (3-D) display, where three liquid crystal display (LCD) panels are stacked in front of a backlight. We have also created an end-to-end system where a real 3D scene captured by a multi-view camera can be reproduced in 3D on this prototype display. Our main contribution lies in the data conversion method using image-based rendering, by which a set of sufficiently dense light field data, which is required for high quality displaying of a 3-D scene, is generated from a sparser set of data that is captured by the multi-view camera.
We have analyzed two limitation factors (upper-bound spatial frequency and anti-aliase condition) of a layered light-field display to derive suitable configurations for the input multi-view images. We have also proposed to use image-based rendering to synthetically generate a set of multi-view images that is suitable as the input.
Toshiaki Fujii (Professor)
Keita Takahashi (Associate Professor)
Toyohiro Saito (former graduate student: --2016.3)
Shu Kondo (former graduate student: --2017.3)
Yuto Kobayashi (former graduate student: --2018.3)